In this blog I will explain the origins and key features of Infrastructure as a Service (IaaS), the core foundations of what we think of as Cloud.
Cloud computing is an evolutionary consequence of a sequence of technology innovations, stretching from human based computing, across generations of hardware and networking, to the advent of virtualisation once hardware was sufficiently fast to allow software to emulate physical equipment. Reliable and broadband internet then allowed virtualisation to be remoted, with IaaS now offering the benefits of low cost, global scale virtualisation to individuals and companies.
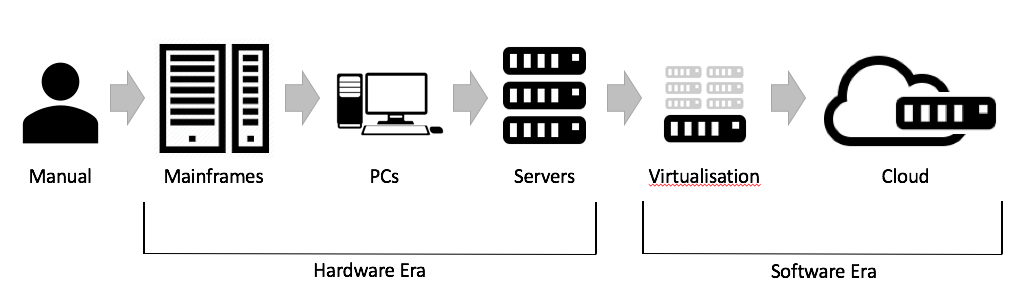
Virtualisation – the catalyst for Cloud
Applications require storage, memory and CPUs to run successfully, and networks to transfer data from one application to another. Storage ensures that data and applications can be accessed when needed; memory allows faster access to these than storage, and CPUs perform the instructions specified by the application to generate the output from the input.
Applications generally don’t interact directly with physical hardware, with operating systems such as Windows, Linux, iOS etc. acting as intermediaries. This separation allows the operating system to perform other tasks, such as running multiple applications simultaneously, and enforcing security by limiting how applications can interoperate.
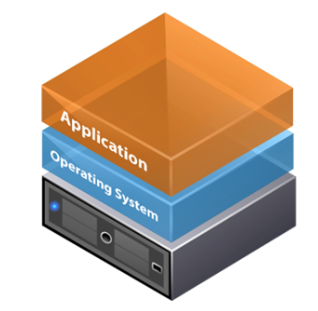
As hardware performance followed Moore’s Law, servers became so powerful that they often ran at only 10-20% of their capacity.
To improve efficiency and save costs, a new virtualisation layer was introduced. This layer controls and isolates virtual servers, where each believes itself to be an isolated server, and acts as their intermediary with the underlying hardware:
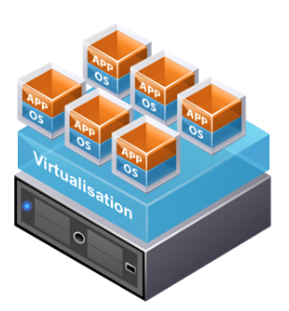
(Images are from the IT Fuel blog, see virtualisation in layman’s terms.)
Virtual servers are easily configurable in terms of their storage, memory, CPU and networking, with the virtualisation layer ensuring that they have the configured amount of resources available. By deploying multiple virtual servers on a single physical server, the hardware’s capacity can be maximised to obtain the efficiency gains.
Virtulisation solved only part of the puzzle
Whilst virtualisation was a major breakthrough in server management and drove the creation of huge fleets of virtual servers, it couldn’t solve other critical pain points:
- Long lead times and high costs for new applications
Hardware was expensive and quickly became obsolete, causing server purchasing to be driven by project demand. Projects continued to have to wait for the procurement and installation cycle (12 weeks was typical), and virtual servers cost almost the same as physical equivalents.
- Inability to respond to customer activity
Lack of spare capacity in virtual server environments meant that successful applications could not be scaled quickly to handle the extra load.
Project teams had to estimate peak load well in advance of the application release and purchase servers accordingly. If this estimate was too high, the servers sat idle and investment was wasted, but if too low then users would experience slow performance or application failures.
- Uncertainty of hardware failure
Whilst running many virtual servers on the same hardware was efficient, operationally it could be difficult to track. This could lead to widespread application outages across the company when hardware failed, and the virtual servers running on it disappeared.
Recovery times were extended as hardware was repaired after failure, often taking days to fit the replacement parts. Users would see experience performance degradation or complete loss of their application.
IaaS – a new paradigm of global immediate virtulisation
Amazon was amongst the first companies to recognise these issues affected all businesses, establishing Amazon Web Services (AWS) to offer storage, networking and compute services that are accessed via the internet. Google Cloud Platform (GCP) and Microsoft Azure soon followed, and these three cloud providers now dominate Cloud.
Cloud providers aimed to provide a cost-effective and efficient alternative to company installed hardware, moving to “pay as you use” pricing and huge capacity across many different hardware types, all delivered within datacentre facilities that were often more secure and robust than companies could construct or lease themselves.
IaaS fundamentally changes both the development of applications and how they are managed in production:
- Virtual servers can be started and stopped when needed, typically in just a few seconds. They are also priced cheaply and are often charged by the second.
- The range of hardware means virtual servers can be run on low spec servers during development and moved to high spec for production, with efficient switching between different server types if required (generally in just a few minutes).
- Applications can use auto-scaling to meet user activity, whereby the processing load on the virtual servers is monitored and extra servers are started automatically when load increases (and then stopped again when activity drops).
Application user interactions are distributed automatically across all the running virtual servers, ensuring an optimal user experience whilst aligning the application’s costs with its actual use:
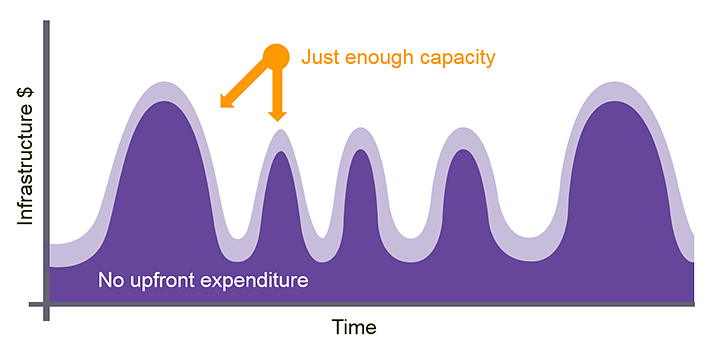
(Image from the AWS Blog, see here)
- Transparent hardware failures
Using auto-scaling, hardware failures trigger replacement virtual servers to start on other hardware, with little or no impact felt by application users.
- Improved security
Virtual servers run within virtual networks, allowing critical applications to be completely isolated, whilst simplifying monitoring of network traffic between servers. This was a major advance over traditional “flat” company networks, where servers could all communicate with each, and which allowed lateral cyber attacks.
- Consistency between development, test and production
The ease of creating new networks and servers means that all environments can be the created identically, allowing robust testing and minimising unexpected production incidents.
- Immediate global reach
Cloud providers have invested heavily in creating datacentre facilities (or regions) around the globe, with virtual servers, network and storage being equally easy to use in any of the regions. Companies can now make decisions about where to deploy applications without being constrained by datacentre locations.
For example, below are AWS regions (blue are existing regions, orange in build):
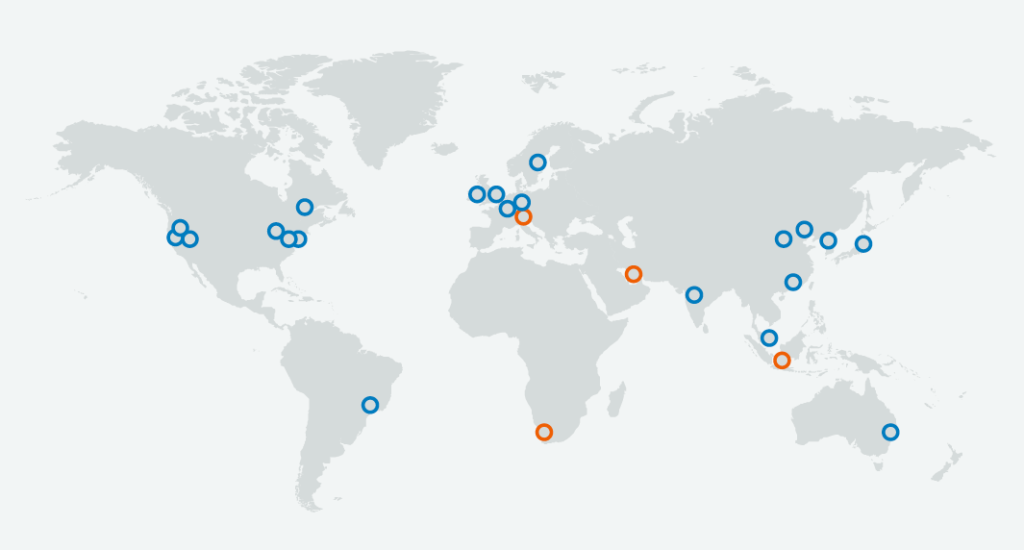
Companies can also create low cost and automated disaster recovery plans, just by using multiple regions and automatically switching users between the regions if an incident occurs.
- Zones within Regions to provide high availability
Regions are designed for resiliency and partitioned into at least two zones. These are close to one another but isolated, so that an incident impacting one zone doesn’t affect other zones. Auto-scaling allows applications to run on virtual servers that are started across multiple zones. This allows companies to decide the level of availability to offer for each of their applications: the more critical the application, the more zones are used.
Summary
We have seen how Infrastructure as a Service (IaaS) extended virtualisation by solving other critical operational and investment issues for companies, at a global scale. IaaS offers companies the ability to experiment at low cost and make changes at much higher cadence.
The success and resilience of IaaS provided the foundation for Cloud evolution towards Platform as a Service (PaaS) and Software as a Service (SaaS), which we will explore in my next blogs.