We are all familiar with Google’s “Did you mean” correction for misspelt search terms.
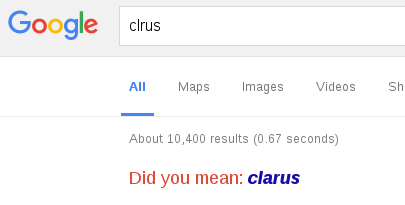
But how does it work? There is a great chapter by Norvig in the book ‘Beautiful Data: The stories behind elegant data solutions’, that discusses and implements a basic spelling corrector, using only a few lines of python code. The chapter is available here on Norvig’s site.

At the heart of any solution is a sense of distance, or similarity, between words (strings in computer code). One of the earliest, and most famous, word distance functions is the so-called Levenshtein Distance (V. Levenshtein 1965) where the distance between two words is defined as the minimum number of character edits needed to convert one string to the other. The edits allowed are inserts, deletes and substitutions of characters in a word. As an example the distance between “clrus” and “clarus” is 1, only one insertion of a character, the letter ‘a’, is needed to make the words equal; the distance between “clxrus” and “clarus” is also 1, only one substitution of a character, the letter ‘a’ for ‘x’, is needed to make the words equal; and finally, the distance between “claraus” and “clarus” is also 1, only one deletion, the second letter ‘a’, is needed to make the words equal. The distance between “clraus” and “clarus” is 2, two substitutions, or one deletion and one insertion, are needed to make the words equal. The edits for the distance need not be a unique combination of edits, the distance is just the minimum number of edits necessary.
Throwing a bone to the math folk, if you have not spotted it already, the Levenshtein distance function satisfies the triangle inequality and forms a metric.
Programmers may well be reminded of the diff utility often used in source code version control, it relies on a similar idea of the minimum number of inserts and deletes except the units are not characters in a word, but complete lines of text in a file.
We have made use of string similarity functions in several areas of data import at Clarus. One basic example, for illustration, is fuzzy matching of the column names in the import of data from CSV (and Excel) files.
When CSV data is produced by a program, it tends to be reliable and well formed, but if the CSV data is produced ‘on-the-fly’ by a human via Excel, there is a reasonable chance for mistakes in the column heading names, the order of the columns, and the format of the data (most notably the date format).
In the most basic implementation of a CSV importing routine, the column headers are ignored and it is trusted that the column order in the file is correct. This works well until a new column is added between existing columns, rather than at the end! A more robust solution is to find the column position based on actual column headings present in the file and then parse the rows of data. To match column headings, the first step is to remove all word separators such as spaces, underscores and hyphens from the column headings, they are only helpful for humans to read (in olden times word separators were not considered necessary at all, see scriptio continua). The next step is to switch the characters in all headings to a specific case, say lowercase, and then determine exact matching headings. At this point column names such as “DiscountFactor”, “Discount Factor”, “DISCOUNT_FACTOR” and “discountfactor” are all matched as the same, this catches many practical and hard-to-spot problem cases, but offers nothing on typos, basic spelling mistakes or inadvertent abbreviations of words. Now should we find any expected column headings still unmatched, then we have a problem on which to use string distance functions. The unmatched expected headings form the dictionary for our spelling corrections, often only one or two words, and so one can proceed and detect the column in the CSV file which is the closest, and sufficiently close to, the expected column name (sometimes referred to as a ‘fuzzy match’) and proceed to import the data without error. A certain amount of calibration is needed on setting the tolerance for ‘closeness’ to avoid false positives, however allowing some flexibility rather than exact matching is of great practical benefit.
Similar situations arise when importing trades, curves and risk scenarios, especially when importing data from customers internal systems; for example, on trades the floating rate index maybe abbreviated in some form, compared to the FpML floating rate option codes.
Our favourite similarity function is the Jaro-Winkler function (rather than the classic Levenshtein function), although not a metric, it deals well with abbreviated words; for example, it can recognise that “DiscFactor” and “DiscountFactor” are reasonably similar.