Anyone working in Capital Markets technology cannot have failed to notice the increase in global identifiers; they now seem to be everywhere for all manner of use cases, some mandatory others best practice.
Often a new identifier is held up as a solution to an existing data problem and is promulgated by regulators as a consequence of which it make its way into systems. Unfortunately as is the way with IT, it is added to existing systems while retaining older legacy identifiers rather than replacing them (as too easy to break processes that rely on the old) and downstream we end up trying to figure out which one identifier to use.
Lets take a look at a few of the more popular identifiers.
Legal Entity Identifier
The most successful of the new identifiers has been the Legal Entity Identifier (LEI), which is a 20-digit alphanumeric code that provides unique identification of legal entities participating in financial transactions and key reference information of these legal entities.

The Global Legal Entity Identifier Foundation (GLEIF), a supra-national not-for-profit organisation, was established by the Financial Stability Board (FSB) to support the implementation and use of LEIs.
A simple measure of LEI’s adoption success is that I can just type in a 20-digit LEI into Google Search and get back a name. Try entering F226TOH6YD6XJB17KS62 yourself.
The first search result takes me to:
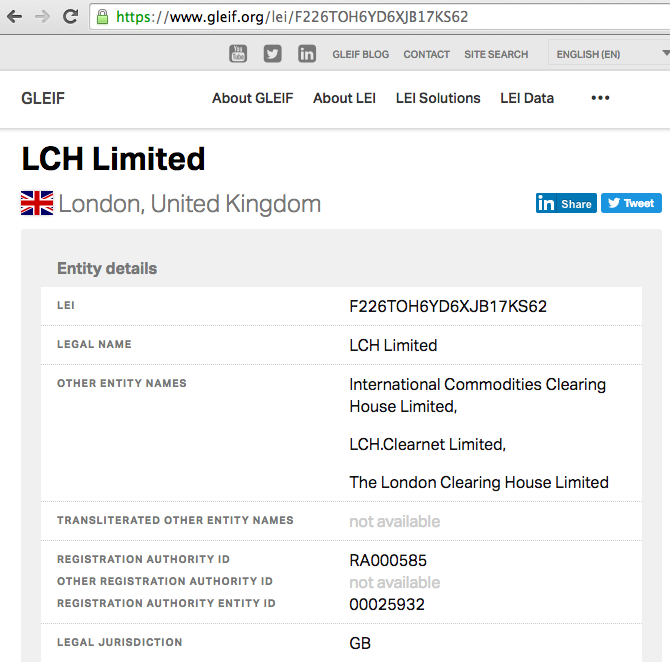
The fact that I can type in a 20-digit LEI string into Google Search in the same way that I would type in “When does next season Silicon Valley start” (Oops, more than a month ago, well it is season 5!) and get the exact result I want is phenomenal and testament to LEIs success (and Google’s).
Having a Legal Entity maintain its own global unique identifier is a massive step forward over each entity maintaining internal identifiers and names for each of their counterparts and we continue to see LEIs adopted in many Systems for many use cases.
Identifiers in Cleared Swaps
As a start point for other identifiers, lets look at the identifiers we can find in the reports of Swaps that are cleared at a CCP e.g. ASX, CME, EUREX, HKEX, JSCC, LCH, SGX.
Generally these will include the following:
Trade Identifiers:
- Cleared Trade Id, issued by the CCP as its own unique identifier
- MarkitWire Trade Id, issued by MarkitServ as most Swaps are affirmed on this
- Unique Swap Identifier (USI), introduced in the US Dodd-Frank regulation for trade reporting
- Unique Trade Identifier (UTI), introduced in EMIR regulation for trade reporting
- (Note these both serve the same purpose and the terms are used interchangeably)
- USI/UTI Prefix, best practice is to now use a prefix derived from the LEI to avoid clashes
Shame there are now so many trade identifiers, but I can understand why.
Product Identifiers:
- Product, Product Type, Taxonomy, and other classification names for financial products
- Unique Product Identifier (UPI), an emerging standard to identify derivative products
Party Identifiers:
- LEIs of the Parties, on each side of the trade, one of which is the CCP for a cleared trade
- LEI of the Venue, on which the trade was executed, e.g. SEF or MTF
Unique Product Identifier (UPI)
Lets concentrate on product identifiers.
In most Derivatives Systems I have worked on, there is an Object Hierarchy for derivatives products, which usually looks something like Product->IRSwap->FixedFloat with the nodes referred to as ProductType and SubType. There a smallish number of these Types and SubTypes but they are different in most Systems, so some might use Swap->EquitySwap or have underlying products.
UPI sounds like a replacement, but for the use case of trade reporting of Derivatives.
More detail in UPI:
- CPMI-IOSCO issued a Technical Guidance in UPIs in September 2017 (available here)
- FSB issued a consultation on UPI governance in October 2017 (available here)
- FSB issues a second consultation on UPI governance in April 2018 (available here)
- (which closes 28 May 2018, gulp, less than 7 days to go!)
One of the things that stands-out for me is on page 22 of the CPMI-IOSCO document.

In summary:
- A 12-character meaningless code e.g. XYZ123REALLY
- A human readable alias may be mapped to the UPI
Personally I don’t agree with either of these, why a 12 character limit in this day and age of technology and why not human readable, that would be so much more useful.
Why not IRSwapFixedFloat? Or some such variation?
All systems I have worked with have had a human readable product code, even at the programming level and this product code has covered both Cash, Securities and Derivatives products; perhaps not for all Asset Classes, but definitely the major ones.
Open FIGI
A comparison of this last point with Open FIGI is instructive.
Human readable and widely known is the Bloomberg Ticker for a USD 10Y IR Swap, which is USSW10.
So I can go to https://openfigi.com/
Enter USSW10 into the search box and get back:
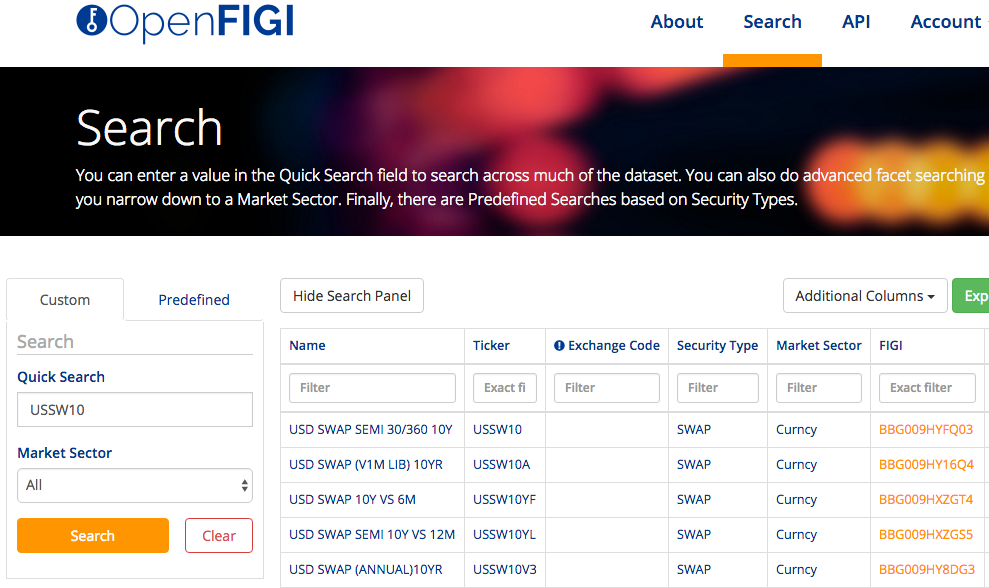
Showing that the Financial Instrument Global Identifier (FIGI) is BBG009HYFQ03, a cryptic 12-character alphanumeric identifier! Perhaps there is method in the madness after-all.
Though here we are getting maturity tenor in the reference data of the product identifier, which will lead to a lot of product identifiers and in most systems I have seen maturity tenor is a separate field.
I guess Product and Instrument are easy to confuse and use interchangeably, the clue is in the name here (FIGI) and I would expect an Instrument symbology to be much more granular than a product one e.g. CME EURODOLLAR JUN18 is an instrument, while FutureMM could be a product code.
MiFID II Transparency
That serves as a nice segue to the topic d’jour (ou mois, ou an); MiFID II Transparency.
(Isn’t Google Translate great, certainly far better than my school level French and that’s without the audio).
When we collect and view the public transparency data for an MTF venue, we can see:
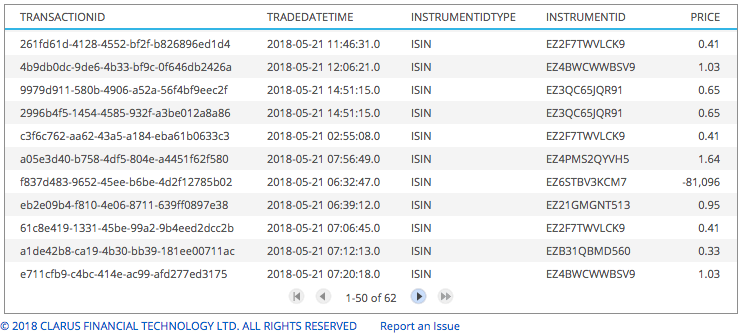
- TransactionId, not sure why this in public data, we certainly have no use for it
- TradeDatetime, the execution time of the trade, very useful
- InstrumentIdType, ISIN, ok a well used identification scheme for bonds
- InstrumentId, a 12-char code (ok, here we go again), now extended to derivatives(really 🙁 )
- Price, that the trade was done at
- …., others not shown
Now to make sense of an ISIN, I can use the DSB-ANA website, (once I figure out what my password is) and enter EZ2F7TWVLCK9 into the search box.
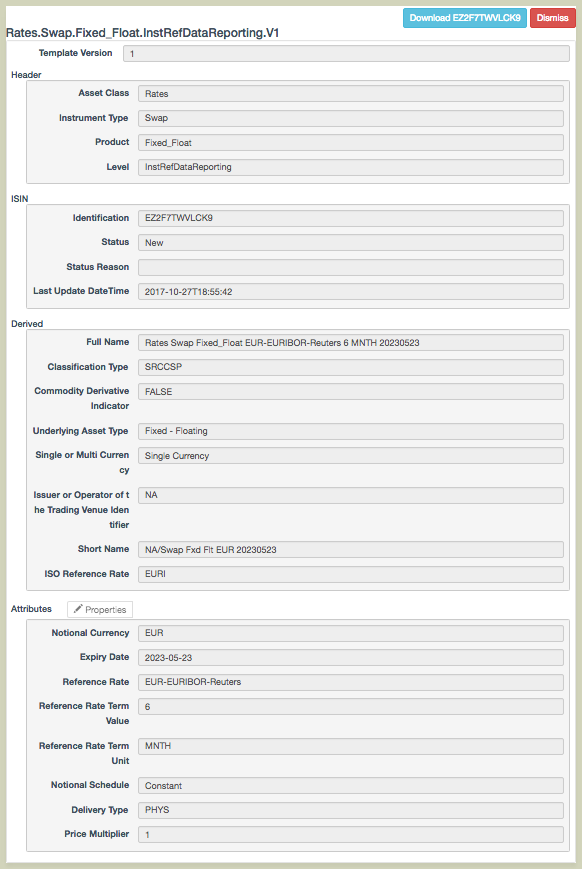
Returning a lot of reference data, including:
- Asset Class: Rates
- Instrument Type: Swap, (instrument type?, well I can learn and remember this one)
- Product: Fixed_Float, (really?, not going to ever remember this)
- Classification Type: SRCCSP (CFI Codes are an ISO standard, this is a good site to view them)
- Single of Multi-Currency: Single (good)
- Short Name: NA/Swap Fxd Flt EUR 20230523 (really, this is not good name)
- Full Name: Rates Swap Fixed_float EUR-EURIBOR-Reuters 6 MNTH 20230523 (ditto, not good)
- Notional Currency, EUR (we all know and use ISO currency codes)
- Expiry Date, 2023-05-23 (hmm, the less said the better, we really really need a period not a date)
- Reference Rate, EUR-EURIBOR-Reuters, (ok, I think the Reuters name here is historic and used)
- Reference Rate Term, 6, (ok, ideally could be joined with below, but fair enough)
- Reference Rate Term Unit, Mnth, (see above)
Which brings me to another key aspect of identifiers, they should link to reference data that is a minimum viable product, to borrow jargon prevalent in Tech Start-Up land.
For LEI, that is a low bar, as a common identifier, legal entity name and jurisdiction is enough value. Of-course, legal-entity hierarchies would also be welcome.
But for an instrument identifier, the reference data is not a low bar, it needs to be sufficiently comprehensive to support common use cases. In the case of MiFID II transparency data, at a minimum we need to be able to aggregate and compare volume and price information by venue and across business days. Unfortunately this is hampered by several short-comings in the reference data
- The use of expiry date instead of maturity period, leads to millions of ISINs, greatly adding to complexity of use and cost of issuing.
- The lack of start period, means forward start swaps, which are very common in FX and Rates are lumped together with spot starting swaps, making a mockery of price comparison.
- Confusing use of either physical or cash for delivery type
I could go on, but will stop there and refer you to my January blog on this topic.
Final Thoughts
A number of new identifiers have been created after the Great Financial Crisis.
The most successful of these is LEI.
LEI is now used in many systems, for regulatory reasons and more.
It is transparent and ubiquitous enough to be deciphered by Google Search.
Adding new identifiers does not mean that legacy ones are replaced e.g. UTI.
UPIs are an interesting identifier and one that may prove contentious.
MiFID II Transparency needs a better Instrument Identifier to ISIN.
Or significant changes to the reference data for derivatives ISINs.
Without a minimum viable product set of reference data, an identifier is useless.
And we would be better off mapping from the names used by each venue to our own scheme.
Or will we see UPI take over from ISIN for MiFID II?
Or should it be OpenFIGI, which is an instrument and not a product code.
Both lack human readability but make use of an alias.
Both are 12 characters (to forestay those IT cost objections 🙂 ).
Only time will tell.
One thing I would like to put out there with regards to the UPI is that Underlying is a required field with in the UPI meta-data construct. Meaning that for Interest Rate Derivatives, there will be a limited number of UPI’s that will be closer to a classification. However, when you move into the Equity space that will quickly expand. For example, there will be a different UPI for a TRS on IBM vs a CFD on IBM. Also there will be a UPI for every stock listed globally for each CFD, Total Return, Price Return, variance, ect.
Great points, as always – fair and well researched analysis. I’ll note that OpenFIGI is in the middle of updating our data sources – so the FIGI that is assigned to the ‘UPI-like’ level on your USSwaps (based on the 3M USD-Libor) will be available via search for all curves. i.e. type BBG006Z3S6W2 into OpenFIGI search. You’ll see it corresponds to the US Dollar Swaps (30/360, S/A) Yield Curve, of which your various tenors (i.e. USSWAP10 (BBG009HYFQ03), USSWAP1 (BBG009HXZSR0), USSWAP3 (BBG009HXZSM5), up through USSWAP50 (BBG009HY6Y88) are all part of. These are further associated with BBG002SBS5T7, which is the ICE LIBOR USD 3 Month Index.
To your point, having a human readable alias is important for usability on interfaces – but the primary key (the FIGI) needs to be semantically meaningless so that you can change the underlying metadata (such as the description) as needed without affecting your data calls.
One of our readers pointed out that “entity hierarchy information is now supported in the LEI data set, even though it’s not currently displayed on the GLEIF search results page. Many of the banks have populated this “level 2 data.”